Cuda 4 - Parallel Optimization Patterns
UDACITY教程 Intro to Parallel Programming
- Basics on GPU, CUDA, Memory Model
- Parallel Algorithms(Reduce, Scan, Histogram, Sort)
- Optimize Parallel GPU Programs
- Others(Library, OpenACC, Dynamic parallelism)
1. Data layout transformation
Global memory coalescing
设计数据结构:AOS Vs. SOA
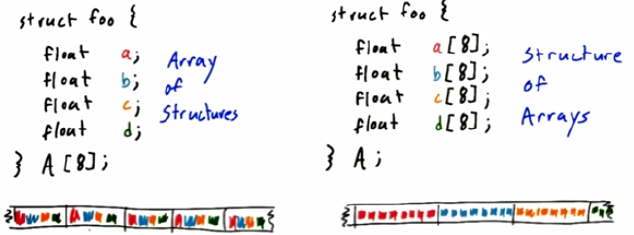
//which is better?
//AOS
int i = threadIdx.x;
A[i].a++;
A[i].b += A[i].c * A[i].d;
//SOA
int i = threadIdx.x;
A.a[i]++;
A.b[i] += A.c[i] * A.d[i];
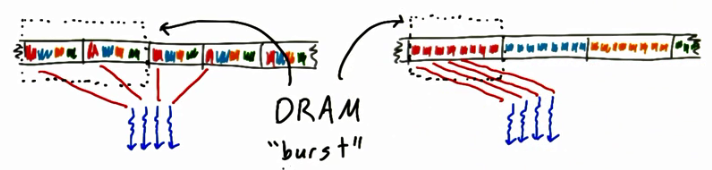 ?AOS会abcd一起取回来吗
?AOS会abcd一起取回来吗
2. Scatter to gather transformation
Scatter: belong to input element, decide where to write
Gather: belong to output element, decide where to get
float third = in[i]/3.0f;
out[i-1] += third;
out[i] += third;
out[i+1] += third;
out[i] = (in[i-1] + in[i] + in[i+1]) / 3.0f;
Scatter: potentially many conflicting writes
Gather: many overlapping reads
3. Tiling
Cache in fast on-chip storage for repeated access
CPU: implicit copy
GPU: explicit copy to shared memory
// both have global memory coalescing
__global__ void foo(float out[], float A[], float B[], float C[], float D[], float E[]) {
int i = threadIdx.x + blockIdx.x*blockDim.x;
out[i] = (A[i] + B[i] + C[i] + D[i] + E[i]) / 5.0f;
}
// below one can utilize tiling
// but the experimental results shows that tiled version is only slightly better
// 可能是因为本身GPU的cache发挥了作用
__global__ void bar(float out[], float in[]) {
int i = threadIdx.x + blockIdx.x*blockDim.x;
out[i] = (in[i-2] + in[i-1] + in[i] + in[i+1] + in[i+2]) / 5.0f;
}
4. Privatization
Good: Threads sharing input
Bad: Threads sharing output
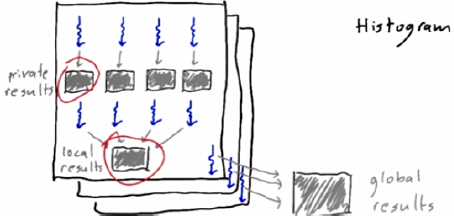
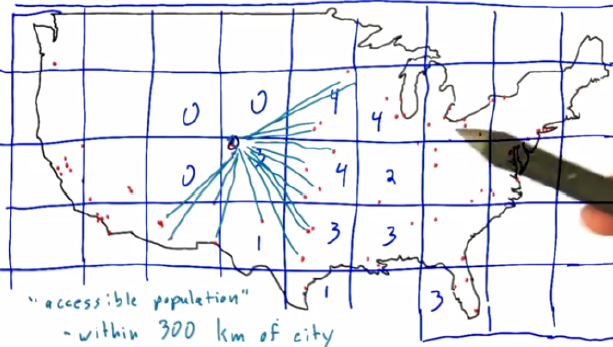
5. Binning
Geographic binning
6. Compaction
if(active) then {do computing}
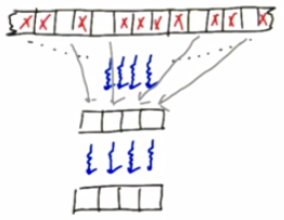
Example: every 8th element will be processed, and computation-intensive
==> 8x faster
7. Regularization
Reorganizing input data to reduce load imbalance