Cuda 1 - Basics on GPU, CUDA, Memory Model
UDACITY教程 Intro to Parallel Programming
- Basics on GPU, CUDA, Memory Model
- Parallel Algorithms(Reduce, Scan, Histogram, Sort)
- Optimize Parallel GPU Programs
- Others(Library, OpenACC, Dynamic parallelism)
1. GPU Architecture
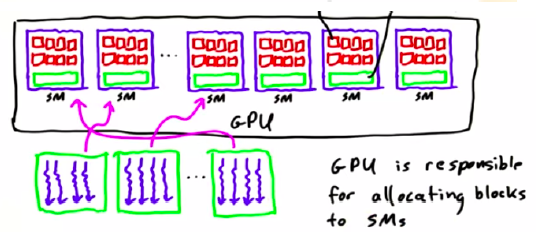
Hardware -> SM: Streaming Multiprocessor, 高度线程化的多核流处理器
Software -> Block: Could run group of threads cooperate to work
One SM –> Multi-Block; Threads in different blocks should not cooperate(even in a same SM)
2. 3-Ways to Accelerate Applications
Libraries, OpenACC Directives, Programming Languages
3. Cuda Kernel
host(cpu): h_var; device(gpu): d_var // 约定写法,h/d开头,区分memory
square<<<1, 64>>> (d_out, d_in); // 尖括号内blocks, threads(512 or 1024 at most)
<<<dim3(bx,by,bz), dim3(tx,ty,tz),shared_mem>>> // 拓展写法4. Problem 1
Convert color image to gray: solution
5. Parallel Communication Patterns
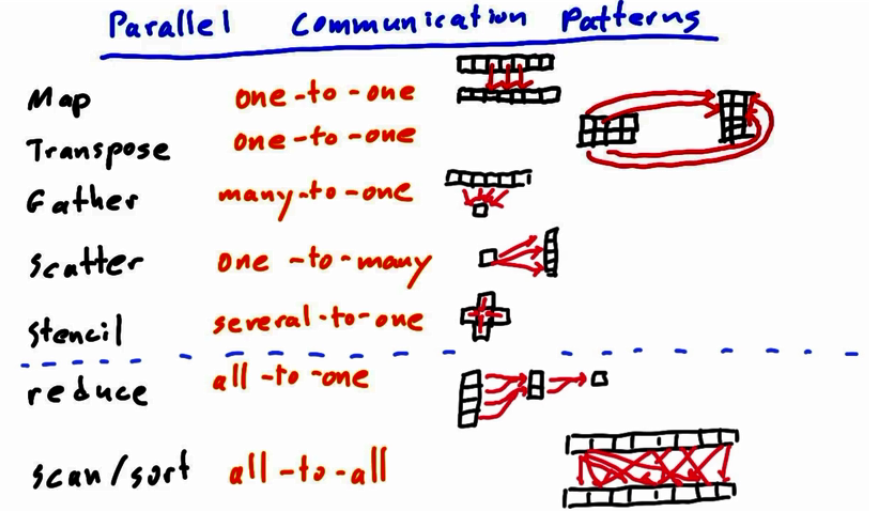
stencil patterns: data reuse, 从特定位置邻居获取data
transpose: reorder data elements in array: array of structures(AOS), structure of arrays(SOA)
out[i + j*128] = in[j + i*128] ==> transpose operation
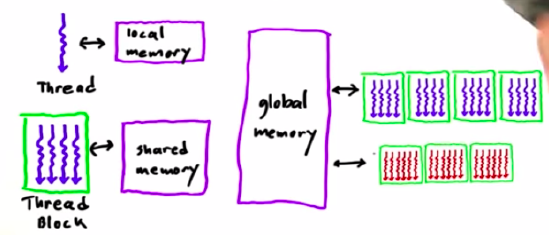
6. Memory Model
Local > Shared >> Global Memory
7. Synchronize & Mutex
同步:__syncthreads()
互斥:atomicAdd() example
8. Problem 2
Image blur: solution
__global__ void blur_kernel(const cv::cuda::PtrStepSz<uchar3> src,
cv::cuda::PtrStepSz<uchar3> dst,
const float* const filter, const int filterWidth) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x >= src.cols || y >= src.rows) return;
vector<float> result(3, 0);
for (int i = 0; i < 3; i++)
for (int filter_r = -filterWidth / 2; filter_r <= filterWidth / 2;
++filter_r) {
for (int filter_c = -filterWidth / 2; filter_c <= filterWidth / 2;
++filter_c) {
int image_y = filter_r + y, image_x = filter_c + x;
if (image_x < 0 || image_x >= src.cols || image_y < 0 ||
image_y >= src.rows) {
continue;
}
uchar3 v = src(image_y, image_x);
float filter_value = filter[(filter_r + filterWidth / 2) * filterWidth +
filter_c + filterWidth / 2];
result[i] += v[i] * filter_value;
}
}
dst(y, x) = uchar3(result);
}
void balance_white_gpu(cv::cuda::GpuMat& src) {
const int m = 32;
int numRows = src.rows, numCols = src.cols;
if (numRows == 0 || numCols == 0) return;
const dim3 gridSize(ceil((float)numCols / m), ceil((float)numRows / m), 1);
const dim3 blockSize(m, m, 1);
cv::cuda::GpuMat dst;
blur_kernel << <gridSize, blockSize>>> (src, dst, filter, filterWidth);
}