Cuda 3 - Optimize GPU Programs
UDACITY教程 Intro to Parallel Programming
- Basics on GPU, CUDA, Memory Model
- Parallel Algorithms(Reduce, Scan, Histogram, Sort)
- Optimize Parallel GPU Programs
- Others(Library, OpenACC, Dynamic parallelism)
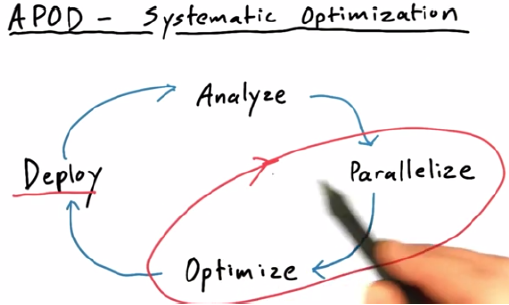
1. APOD
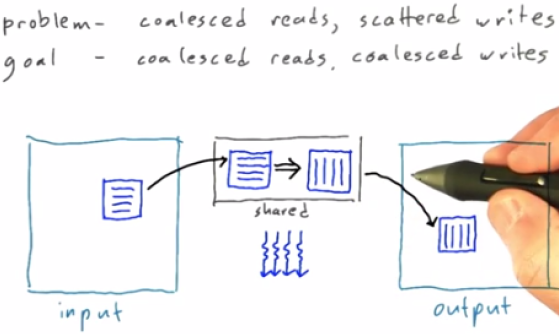
2. HotsPots
Amdahl’s Law:
max speedup = 1 / (1-p) (p is portion can be parallelized)
y: the total speedup, x: the portion can be speedup
y = 1 / (1-p + p/x) ==> y = x / ((1-p)x + p)
if x is much bigger than p, y = 1 / (1-p)
3. Occupancy

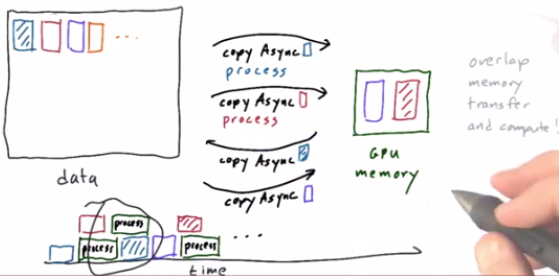
4. WARP-Avoid Thread Divergence
Set of threads that execute the same instructions at a time
Nvidia Card is 32, so:
switch(threadIdx.x / 32) {case 0...31} // no slowdown
switch(threadIdx.x % 32) {case 0...31} // 32x slowdown5. Streams
Sequence of operations execute in order(memory transfers, kernels)
cudaStream_t s1, s2;
// behaviour is full concurrency: default stream also maps to a single Stream
// https://devblogs.nvidia.com/parallelforall/gpu-pro-tip-cuda-7-streams-simplify-concurrency/
// cudaStreamCreateWithFlags(&s1, cudaStreamNonBlocking);
// 这里注意,cudaMemcpyAsync只是说这个func是异步返回,具体内部是否能完全把2个copy+计算并行化,还需要3个必要条件
// 1. host用pinned memory,用cudaMallocHost 2. 放到不同的stream 3. 这个gpu卡上有free DMA copy engine
// 否则,这个asycn的copy调用,行为上就退化到和cudaMemcpy一样,只是说最终host thread会卡在cudaDeviceSynchronize而已
// https://stackoverflow.com/questions/14093601/effect-of-using-page-able-memory-for-asynchronous-memory-copy、
cudaStreamCreate(&s1);
checkCudaErrors(cudaMemcpyAsync(d_fimTheta, out_t, numbytes, cudaMemcpyHostToDevice, s1));
cudaStreamCreate(&s2);
checkCudaErrors(cudaMemcpyAsync(d_fimMag, out_m, numbytes, cudaMemcpyHostToDevice, s2));
A<<<1, 1024, s1>>>(d_fimTheta);
B<<<1, 1024, s2>>>(d_fimMag);
cudaDeviceSynchronize();
cudaStreamDestroy(s1); cudaStreamDestroy(s2);6. Summary

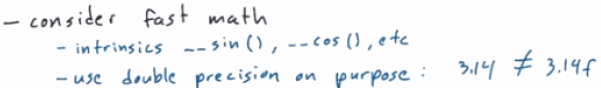

7. Problem 5
Fast histogram: Fast histogram